Spatial VLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
† Work done while interning at Google DeepMind.
* Equal contribution alphabetically.
CVPR 2024



CVPR 2024

Motivation: Humans effortlessly determine spatial relationships, such as the positioning of objects relative to each other or estimating distances and sizes. This natural proficiency in direct spatial reasoning tasks contrasts with the current limitations of VLMs. Can we imbue VLMs with spatial reasoning abilities akin to those of humans?
Key insight: We hypothesize that the limited the spatial reasoning abilities of current VLMs is not due to a fundamental limitation of their architecture, but rather is a limitation in common datasets available at scale on which such models are trained. We co-train a multimodal large language model on synthetic spatial data to investigate this hypothesis.
We develop an automatic 3D spatial VQA data generation framework that lifts 2D images into metric scale 3d point clouds. We scales the data pipeline up to 2 billion VQA examples on 10 million real-world images.
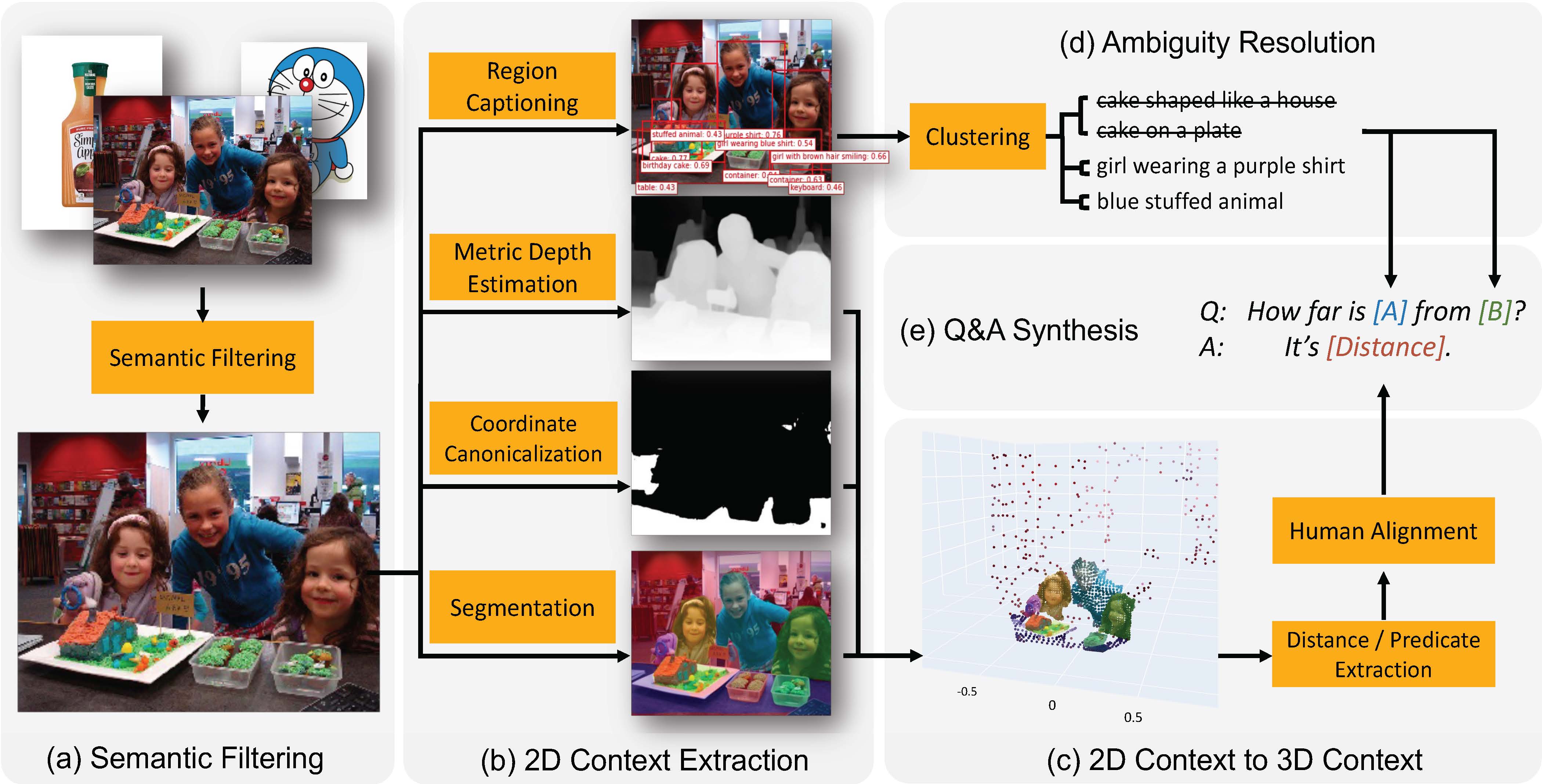
We then mix the synthesized data into the training set of a multimodal large language model to train Spatial VLM. Such data allows the model to answer intuitive spatial reasoning questions such as the ones listed in the figure below. These elemental abilities serves as the building block for more complex spatial reasoning tasks such as those require multiple steps.
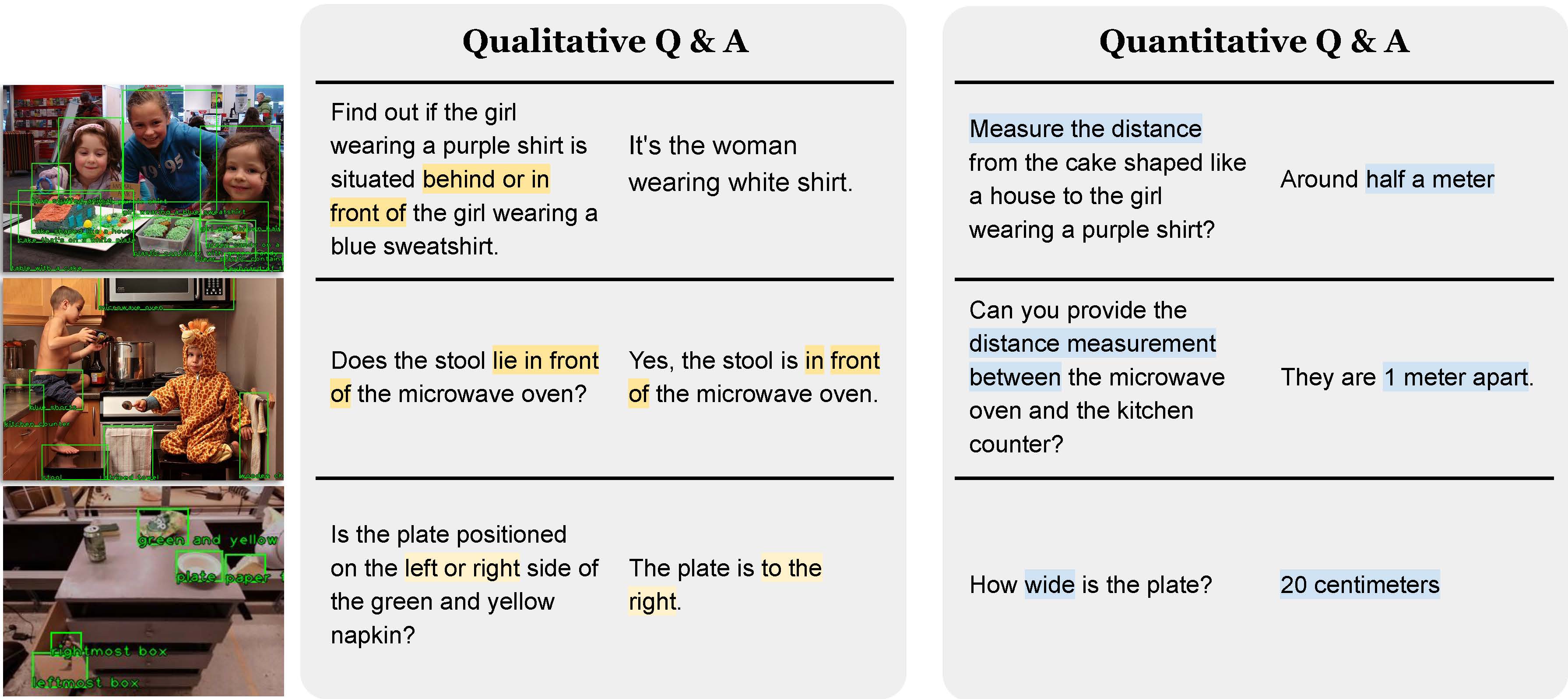
In the figure below, we listed some sample question & answer pairs generated by our pipeline.
With the ability to perform direct spatial reasoning like humans, we can let SpatialVLM perform Chain-of-Thought Spatial reasoning by letting it talk with with an LLM. As we will show later in experiments section, the direct reasoning capabilities, when combined with chain-of-thought reasoning can answer many multi-step questions.
Through extensive benchmark, we found our proposed framework can significantly enhance the ability of visual language models in performing different types of spatial reasoning like humans, as well as unlocking novel downstream applications such as robotics.
When prompted to answer free-form binary predicate prediction question, such as which object is closer to the viewer, SpatialVLM outperforms baselines on by a large margin owing to the addition of synthetic data.


When finetuned with unfreezed image encoder, SpatialVLM can be prompted to answer quantitative spatial estimation question, such as the horizontal distances between objects. In particular, SpatialVLM outputs valid format more often than baseline methods when prompted to. In addition, SpatialVLM outputs quantitative distance estimation that is closer to ground truth annotated by human more often than baseline methods, with 37.2% of its answers falling with in 0.5x-2x range of the ground truth.


In this example, with the help of an LLM orchestrating Spatial VLM,the system is able to answer questions like “Does the blue coke can, the red coke can, and the greensponge on the table roughly form an equilateral triangle". This opens up future opportunities to generate more complex spatial reasoning questions and answers to train a unified multimodal large lagnuage model.

Due to its ability to intuitively reason about space quantiatively in real-world units, SpatialVLM can be used as a fine-grained reward-annotator for robotics tasks. In the figure below, SpatialVLM correctly assigns a monotonically decreasing distance estimation for an robot hand approaching a coke can, which can be used as a reward signal for reinforcement learning.

In the figure below, we show SpatialVLM can be prompted to annotate dense rewards for open-vocabulary robotic tasks, unlike many prior methods that can only annotate a binary label of success or failure.

After releasing this paper, we were greeted with enthusiasm by the VLM research community. A shout-out to a user named remyxai for providing an open-source implementation of the data synthesis pipeline that closely follows our method. Check it out at: https://github.com/remyxai/VQASynth

Special thanks Ying Xu and Chuyuan Kelly Fu for their help in creating evaluation dataset, and thank Andy Zeng and Vincent Vanhoucke for feedbacks on early drafts of this paper. Thanks to remyxai for providing an open-source implementation of the data synthesis pipeline.
@InProceedings{Chen_2024_CVPR,
author = {Chen, Boyuan and Xu, Zhuo and Kirmani, Sean and Ichter, Brain and Sadigh, Dorsa and Guibas, Leonidas and Xia, Fei},
title = {SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {14455-14465}
}If you are using the open source implementation listed above, please also cite:
@misc{VQASynth,
author = {remyxai},
title = {VQASynth},
year = {2024},
note = {GitHub repository},
url = {https://github.com/remyxai/VQASynth/tree/main}
}